Churn prediction
Churn prediction is the task of identifying of users/customers that are likely to stop using a service/product/website. With this toolkit, you can accurately forecast the probability that a customer is likely to churn using raw usage/activity logs.
Introduction
A churn predictor
model
learns historical user behavior patterns in-order to make an accurate forecast
for the probability of in-activity in the future (defined as churn).
What is Churn?
Churn can be defined in many ways. We define churn to be no activity within
a period of time (called the churn_period). Using this definition, a
user/customer is said to have churned any form of activity is followed by no
activity for an entire duration of time known as the churn_period (by
default, we assume 30 days). The following figure better illustrates this
concept.
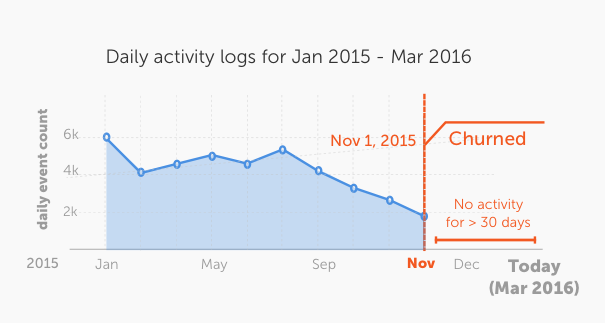
A churn forecast is always associated with a particular timestamp (at which the
churn_period starts). We refer to this timestamp as the time_boundary. An
en example, a user churning at the time_boundary Jan 2015 implies the user
showed activity before Jan 2015 but then had no activity for a churn_period
of time after Jan 2015.
Input Data: Raw event logs
A churn prediction model can be trained on time-series of observation_data.
The time-series must contain a column named user_id and atleat one other
column that can be treated as a feature column. The following example depicts a
typical dataset that can be consumed directly by the churn predictor.
+---------------------+------------+----------+
| InvoiceDate | CustomerID | Quantity |
+---------------------+------------+----------+
| 2010-12-01 08:26:00 | 17850 | 6 |
| 2010-12-01 08:26:00 | 17850 | 6 |
| 2010-12-01 08:26:00 | 17850 | 8 |
| 2010-12-01 08:26:00 | 17850 | 6 |
| 2010-12-01 08:26:00 | 17850 | 6 |
| 2010-12-01 08:26:00 | 17850 | 2 |
| 2010-12-01 08:26:00 | 17850 | 6 |
| 2010-12-01 08:28:00 | 17850 | 6 |
| 2010-12-01 08:28:00 | 17850 | 6 |
| 2010-12-01 08:34:00 | 13047 | 32 |
| 2010-12-01 08:34:00 | 13047 | 6 |
| 2010-12-01 08:34:00 | 13047 | 6 |
| 2010-12-01 08:34:00 | 13047 | 8 |
| 2010-12-01 08:34:00 | 13047 | 6 |
| 2010-12-01 08:34:00 | 13047 | 6 |
| 2010-12-01 08:34:00 | 13047 | 3 |
| 2010-12-01 08:34:00 | 13047 | 2 |
| 2010-12-01 08:34:00 | 13047 | 3 |
| 2010-12-01 08:34:00 | 13047 | 3 |
| 2010-12-01 08:34:00 | 13047 | 4 |
+---------------------+------------+----------+
[532618 rows x 5 columns]
In the above dataset, the last timestamp was October 1, 2011. If we assume that
the churn_period was defined as 1 month, a churn prediction (or forecast)
predicts the probability that a user will have no activity for a 1 month period
into the future (i.e. November 1, 2011).
Introductory Example
In this example, we will explore the task of predicting churn directly from customer activity logs. The following dataset contains transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail.
In this example, we will train a churn-predictor with a few lines of code.
import graphlab as gl
import datetime
# Load a data set.
raw_data = gl.SFrame('http://s3.amazonaws.com/dato-datasets/churn-prediction/online_retail.csv')
# Convert InvoiceDate from string to a Python datetime.
import dateutil
from dateutil import parser
sf['InvoiceDate'] = sf['InvoiceDate'].apply(parser.parse)
# Convert the SFrame into TimeSeries with InvoiceDate as the index.
time_series = gl.TimeSeries(raw_data, 'InvoiceDate')
# Split the data using the special train, validation split.
train, valid = gl.churn_predictor.random_split(time_series,
user_id='CustomerID', fraction=0.9)
# Define the period of in-activity that constitutes churn.
churn_period = datetime.timedelta(days = 30)
# Train a churn prediction model.
model = gl.churn_predictor.create(train, user_id='CustomerID',
features = ['Quantity'],
churn_period = churn_period)
Warning: When parsing the dataset, expect a few warnings. The dataset, as obtained from its original source, has some malformed rows. We will ignore those rows while making predictions.
Predicting churn (in the future)
The goal of a churn prediction model is to predict the probability that a user
has no activity for a churn_period of time in the future. Hence, the output
of this model is a forecast of what might happen in the future. The
following example illustrates this concept.
model.predict(time_series)
+------------+-----------------+
| CustomerID | probability |
+------------+-----------------+
| None | 0.0661627277732 |
| 12346 | 0.67390537262 |
| 12347 | 0.760785758495 |
| 12348 | 0.62475168705 |
| 12349 | 0.372504591942 |
| 12350 | 0.67390537262 |
| 12352 | 0.201043695211 |
| 12353 | 0.821378648281 |
| 12354 | 0.737500548363 |
| 12355 | 0.699232280254 |
+------------+-----------------+
[4340 rows x 2 columns]
Evaluating the model (post-hoc analysis)
Unlike most other toolkits, it can be safe to evaluate the model on the same
data on which it was trained (although not recommended). The
:func:~graphlab.churn_predictor.random_split function provides a safe way to
split the observation_data into a train and validation split specially for
the task of churn prediction.
The recommended way to evaluate a churn prediction model is to perform post-hoc
analysis using historical data. In other words, we first simulate what the
model would have predicted at a time_boundary in the past and compare those
predictions with the ground truth obtained from events after the
time_boundary.
eval_time = datetime.datetime(2011, 10, 1)
metrics = model.evaluate(valid, time_boundary = eval_time)
{
'auc' : 0.6634142545907242,
'recall' : 0.6243386243386243,
'precision': 0.6310160427807486,
'evaluation_data':
+------------+-----------------+-------+
| CustomerID | probability | label |
+------------+-----------------+-------+
| 12348 | 0.93458378315 | 1 |
| 12361 | 0.437742382288 | 1 |
| 12365 | 0.5 | 1 |
| 12375 | 0.769197463989 | 0 |
| 12380 | 0.339888572693 | 0 |
| 12418 | 0.15767210722 | 1 |
| 12432 | 0.419652849436 | 0 |
| 12434 | 0.88883471489 | 1 |
| 12520 | 0.0719764530659 | 1 |
| 12546 | 0.949095606804 | 0 |
+------------+-----------------+-------+
[359 rows x 3 columns]
'roc_curve':
+-----------+-----+-----+-----+-----+
| threshold | fpr | tpr | p | n |
+-----------+-----+-----+-----+-----+
| 0.0 | 1.0 | 1.0 | 189 | 170 |
| 1e-05 | 1.0 | 1.0 | 189 | 170 |
| 2e-05 | 1.0 | 1.0 | 189 | 170 |
| 3e-05 | 1.0 | 1.0 | 189 | 170 |
| 4e-05 | 1.0 | 1.0 | 189 | 170 |
| 5e-05 | 1.0 | 1.0 | 189 | 170 |
| 6e-05 | 1.0 | 1.0 | 189 | 170 |
| 7e-05 | 1.0 | 1.0 | 189 | 170 |
| 8e-05 | 1.0 | 1.0 | 189 | 170 |
| 9e-05 | 1.0 | 1.0 | 189 | 170 |
+-----------+-----+-----+-----+-----+
[100001 rows x 5 columns]
'precision_recall_curve':
+---------+----------------+----------------+
| cutoffs | precision | recall |
+---------+----------------+----------------+
| 0.1 | 0.568181818182 | 0.925925925926 |
| 0.25 | 0.6138996139 | 0.84126984127 |
| 0.5 | 0.631016042781 | 0.624338624339 |
| 0.75 | 0.741935483871 | 0.243386243386 |
| 0.9 | 0.533333333333 | 0.042328042328 |
+---------+----------------+----------------+
[5 rows x 3 columns]
}
Accessing the underlying features & model
The churn predictor allows access to the underlying features and boosted tree model that created the forecast.
# Get the trained boosted trees model.
bt_model = model.trained_model
# Get the training data after feature engineering.
train_data = model.processed_training_data
Model training explained
There two stages during the model training phase:
- Phase 1: Feature engineering. In this phase, features are generated
using the provided activity data. For this phase, only the data before
the provided
time_boundaryis used. The data after thetime_boundaryis used to infer the prediction target (labels). - Phase 2: Machine learning model training. In this phase, the computed features and the inferred labels are used to train a classifier model (using boosted trees).
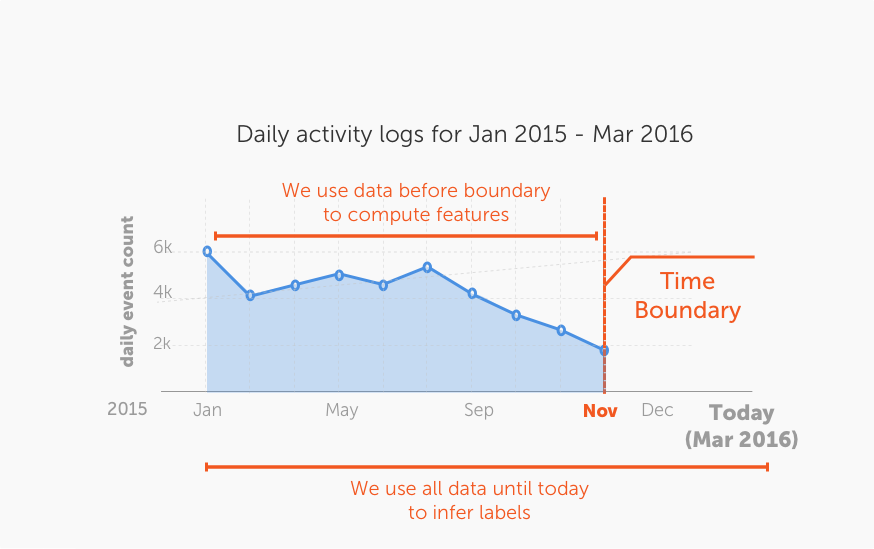
For Phase 1, this toolkit performs a series of extremely rich set of feature transformations based on:
- aggregate statistics (over various periods of time) of the raw input feature columns.
- patterns over various period of time (e.g. rate of change of aggregate usage).
- user metadata (using the
user_dataparameter),
For Phase 2, a classifier model is trained using gradient boosted trees. Note that a churn prediction model can be trained without any labelled data. All the target labels required for training the boosted tree model are inferred based on the activity data from the past. For example, a dataset that contains data from January 2015 to December 2015 contains historical information about whether or or a user churned during each of the months prior to November 2015.
For a given time_boundary (say October 2015), all the events in
observation_data after October 2015 are not (and must never be) included in
the training data for the model. In order to create more training data for the
boosted tree classifier, multiple time-boundaries can be used (using the
parameter time_boundaries)
Alternate data format: Aggregated event logs
The churn prediction model performs a series of feature engineering steps. The
first of the many feature transformations involves a re-sample operation which
aggregates data into a fixed granularity/time-scale e.g. daily, weekly, or
monthly (defined by time_period). If your data is already aggregated at a
granularity level that is of interest to you, then you can skip this step with
the option is_data_aggregated = True.
+---------------------+------------+----------------+
| InvoiceDate | CustomerID | Sum(Quantity) |
+---------------------+------------+----------------+
| 2010-12-01 00:00:00 | 17850 | 26997 |
| 2010-12-02 00:00:00 | 17850 | 31310 |
| 2010-12-03 00:00:00 | 17850 | 15121 |
| 2010-12-04 00:00:00 | 17850 | None |
| 2010-12-05 00:00:00 | 17850 | 16451 |
| 2010-12-06 00:00:00 | 17850 | 21718 |
| 2010-12-07 00:00:00 | 17850 | 25099 |
| 2010-12-08 00:00:00 | 17850 | 23039 |
| 2010-12-09 00:00:00 | 17850 | 18942 |
| 2010-12-10 00:00:00 | 13047 | 20961 |
| 2010-12-11 00:00:00 | 13047 | None |
| 2010-12-12 00:00:00 | 13047 | 10603 |
| 2010-12-13 00:00:00 | 13047 | 17727 |
| 2010-12-14 00:00:00 | 13047 | 20727 |
| 2010-12-15 00:00:00 | 13047 | 18488 |
| 2010-12-16 00:00:00 | 13047 | 29947 |
| 2010-12-17 00:00:00 | 13047 | 16959 |
| 2010-12-18 00:00:00 | 13047 | None |
| 2010-12-19 00:00:00 | 13047 | 3799 |
| 2010-12-20 00:00:00 | 13047 | 15793 |
+---------------------+------------+----------------+
[37459 rows x 2 columns]
Side information for users
In many cases, additional metadata about the users can improve the quality of the predictions. For example, including information about the geographic location of the customer, age, profession etc. can be useful information while making predictions. We call this type of information user side data.
The user_data parameter is an SFrame and must have a user column that
corresponds to the user_id column in the observation_data. The churn
prediction toolkit automatically joins the data to the computed feature table
from Phase 1 before training the boosted tree model.
side_data = gl.SFrame('http://s3.amazonaws.com/dato-datasets/churn-prediction/online_retail_side_data.csv')
# Train a churn prediction model.
model = gl.churn_predictor.create(train, user_id='CustomerID',
features = ['Quantity'],
churn_period = churn_period,
user_data = side_data)
# Make predictions
predictions = model.predict(valid, user_data = side_data)
# Evaluate the model
evaluation_time = datetime.datetime(2011, 10, 1)
metrics = model.evaluate(valid, evaluation_time, user_data = side_data,)
+------------+----------------+
| CustomerID | Country |
+------------+----------------+
| 13050 | United Kingdom |
| 14515 | United Kingdom |
| 16257 | United Kingdom |
| 17885 | United Kingdom |
| 13560 | United Kingdom |
| 15863 | United Kingdom |
| 14406 | United Kingdom |
| 13518 | United Kingdom |
| 14388 | United Kingdom |
| 16200 | United Kingdom |
+------------+----------------+
[4340 rows x 2 columns]